How to block AI Crawler Bots using robots.txt file
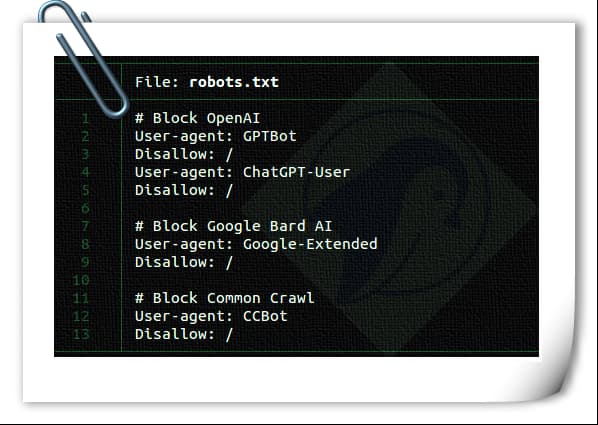
Are you a content creator or a blog author who generates unique, high-quality content for a living? Have you noticed that generative AI platforms like OpenAI or CCBot use your content to train their algorithms without your consent? Don’t worry! You can block these AI crawlers from accessing your website or blog by using the robots.txt file.
A robots.txt is nothing but a text file instructs robots, such as search engine robots, how to crawl and index pages on their website. You can block/allow good or bad bots that follow your robots.txt file. The syntax is as follows to block a single bot using a user-agent: user-agent: {BOT-NAME-HERE} disallow: / Here is how to allow specific bots to crawl your website using a user-agent: User-agent: {BOT-NAME-HERE} Allow: / Where to place your robots.txt file?
Upload the file to your website’s root folder. So that URL will look like: https://example.com/robots.txt https://blog.example.com/robots.txt See the following resources about robots.txt for more info: Introduction to robots.txt from Google. What is robots.txt? | How a robots.txt file works from Cloudflare. How to block AI crawlers bots using the robots.txt file The syntax is the same: user-agent: {AI-Ccrawlers-Bot-Name-Here} disallow: /

